Update: see also followup post
Clang built Firefox is claimed to outperform GCC, but it is hard to get actual numbers. Firefox builds switched from GCC 6 builds (GCC 6 was released in 2016) with profile guided optimization (PGO) to Clang 7 builds (latest release) which in addition enable link time optimization (LTO). Link-time optimization can have important performance and code size impact.
Martin Stránský (RedHat maintainer of the Firefox package) compared GCC 8 built binary with Clang 7, and his setup was not completely comparable either because of the stack protector settings and other security centric system-wide defaults of Fedora. Moreover GCC -O2 defaults are (in my opinion unfortunately) still not enabling vectorization and unrolling which may have noticeable effects on benchmarks. This is a historical decision bit motivated by pressure Clang gave on us with compile times. This has changed. I am in process of evaluating what can be done with this default.
For my testing. I built LTO and PGO enabled Firefox using GCC 8 (sadly no official release since I had to fix one bug) and Clang 7 and compared them to two official Firefox binaries:
- last release built with GCC: Firefox 63, and
- first release build with Clang: Firefox 64.
Summary
To summarize my findings, I found that watchdog in Firefox kills the training run before it had time to stream profile data to disk. This bug in Firefox build system has bad effect on performance, because compiler has only partial profile data. Fixing this issue leads to faster binaries. GCC is a lot more careful about binary size (Clang builds have 48% bigger code section!) but for tasks which are covered by train run GCC 8 LTO+PGO binary performs well (and win in benchmarks I tried). It is probably possible to find benchmarks that test things not covered by train run where GCC code will likely perform slower than Clang because it is a lot smaller. However benchmarks I found discussed in the Fedora ticket above all like GCC. Clang currently builds about 10% faster, I hope to reverse the sides with GCC 9 :)Comparing compiler performance on such a complex project as Firefox is delicate job. I plan to get Firefox's benchmark infrastructure (Talos) running again and do more detailed analysis which also compare GCC 9.
You can compare this with my earlier tests of Firefox
- 2010: Optimizing real world applications with GCC Link Time Optimization
- 2015: Link time and inter-procedural optimization improvements in GCC 5
- 2014: Linktime optimization in GCC, part 2 - Firefox
- 2018: GCC 8: link time and interprocedural optimization
- 2018: Building openSUSE with link-time optimizations
Try it
I have uploaded a binary build with GCC 8, with link-time optimization and profile feedback. If your curiosity exceeds the fear of running random binaries from the net, you are welcome to try it out. It is built from Firefox 64 release. You can compare it to the official build and build provided by your favourite distro. (Is there an stable link to the Firefox 64 official Linux binary?)I am just typing my post using it and it seems to work on both Debian and Tumbleweed distros.
Profile data collection problem
PGO in Firefox build system is automated. If enabled in mozconfig, the build first produces a binary with profile instrumentation, then starts a local webserver and trains the application on few things (there is Speedometer, SunSpider and few other things I did not immediately recognize) and proceeds by building the final binary next.One problem is that if train run fails, the build system will not inform you. For example, if you do not have X server available, your binary will be effective on printing error message but nothing else. Sometimes the train run crashes and then the code quality goes completely off. I learnt the habit of using Xvnc and observing the train run remotely to check that it does what it should. I am surprised that Firefox developers did not added a check that each of the tasks has finished successfully. It would be useful as a regression suite, too.
Issue I run into this time is bit subtle. It is not visible during testing but it can be seen as following message in the build log:
MOZ_CRASH(Shutdown too long, probably frozen, causing a crash.) at /aux/hubicka/firefox-2018/release/toolkit/components/terminator/nsTerminator.cpp:219This message (hidden between 57958 others) basically means that the worker threads was killed during exit and thus the profile data collected from the actual training benchmark was never saved to disk (and thus invisible to the compiler). It turns out that this is a timeout in Firefox internal watchdog that kills individual subprocesses if they seems to have hanged up during exit. GCC profiling runtime streams all data from the global destructor in libgcov library and for Firefox it may take some time. GCC profile data is organized into multiple files (one for every object file) while Clang's is one big file which is later handled by specialized tool. I suppose one large file may be faster to write than 8k smaller files.
I use this patch to increase the timeout for training runs.
Update: Thanks to Nathan Froyd I have set up myself as Firefox developer and tried to produce cleaner patch for review https://bugzilla.mozilla.org/show_bug.cgi?id=1516081
GCC LTO bug
Fixing the PGO collection problem finally got me optimized binary, this time it however did not start. Problem is caused by a long standing bug in GCC command line option handling where command line options was incorrectly merged for the function wrapping global constructor. This led to enabling AVX and since the global constructor now gets some code auto-vectorized the binary crashed on invalid instruction during the build (my testing machine has no AVX).Update: As pointed out at ycombinator, the invalid instructions was actually AVX2, Bulldozer supports AVX.
I have now fixed this for GCC 8 and mainline and plan to backport it to GCC 7. So to reproduce my builds, you either new recent GCC 8 snapshot or you can work-around by disabling the cdtor merging pass by using -fdisable-ipa-cdtor.
This optimization combines static constructors and destructors from individual translation units into single function. It was in fact also motivated by Firefox which used to have many constructors (remember, each time you include iostreams you implicitly get one) and running them caused important lag during startup accessing many parts of the code segments. It seems that this problem was fixed by hand over the time and thus this optimization is not very important for Firefox anymore.
This bug affect link-time optimized builds only where correct behaviour with respect to the optimization options passed at compile-time is quite challenging. This bug needs several factors to trigger - one needs to have at least one file build with AVX codegen enabled, object files needs to be passed in right order, there needs to be global constructor which is autovectorizable and one needs to execute final binary on CPU without AVX support. I suspect that this also may be origin of the problem with Firefox crashing at startup seen by RedHat guys recently.
LTO module is intrusive change to the whole toolchain and unfortunately because the LTO adoption is still pretty low surprises happens. At SUSE we now work actively on enabling link-time by default after switching to GCC 9. Hopefully this will hammer out similar issues. At the moment only about 500 out of 11k packages fails to build with link-time optimization some for a good reasons. We will concentrate on fixing the issues prior GCC 9 release.
File size
While I did not manage to 100% match the Firefox official builds, it seems that my Clang 7 build is close enough to make comparision meaningful.
48% code segment size increase for switching compilers is little bit surprising. I think there are two factors affecting this.
- GCC is more aggressive to optimize for size regions that was not trained.
- The traditional LTO where whole program is loaded back to compiler which runs it through the back-end as if it was all one compilation unit is too slow in practice. Both GCC and Clang use to more scaleable model (you can get traditional LTO with -flto-partition=none for GCC and -flto=full for Clang).
The faster LTO modes necessarily trades some code quality for performance. This is where both compilers differs. GCC's LTO was designed to run whole inter-procedural optimization queue using summaries and later dispatch local optimization into multiple worker processes, while Clang's thin LTO is built around assumption that GCC's approach will not scale enough and works differently. Thin linker does just part of inter-procedural optimization decisions and rest of translation is per-file based..
Time will tell which of the approaches will scale better. I find it interesting challenge to get GCC build times on par or better than Clangs even for project of size of Firefox. It would be always possible to combine both approaches if linking bigger applications than Firefox becomes important. So far I do not have a testcase to play with.
Understanding performance of builds with PGO enabled
The train run of Firefox covers about 15% of the whole binary. Bear in mind that benchmarking code that was not at all trained during the build will make you to measure performance of code optimized for size (and it won't be very good). This can be handled by improving the train run coverage in Firefox or disabling PGO for those modules where it can not be done (such as hardware specific video decoders).This makes direct GCC to Clang comparison bit harder, because Clang seems to not optimize for size cold regions or do that a lot less aggressively.
I believe GCC's default is correct one because size of binaries matters in practice, but it may not be best one in all scenarios. If it would seem useful, I can provide command line option for GCC that will disable aggressive code size optimizations for cold parts of the program.
GCC and Clang also differs in a way they interpret -Os. For GCC it means "do everything possible to get smaller binary", while for Clang it seems to be more "disable some of the most code size expensive optimizations". Clang provides -Oz that is closer to what GCC's -Os have. For a while I was thinking that having such less aggressive size optimization in GCC would be also useful especially in scenarios where GCC auto-guesses cold regions and there is chance that it was wrong. This is not hard to implement and may be something to do next year.
Benchmarks
I started with SunSpider and Speedometer benchmarks which I have noticed are part of the default train run. This makes most apple-to-apple comparison of abilities of code generators without being affected by choice of code quality for cold regions of the binary. Of course in practice binaries are never perfectly trained and thus I also include other benchmarks if you scroll down.Sometimes more is better and sometimes it is the opposite. I always ordered data from best run to worst for easy orientation.
Sunspider is now somewhat historical javascript benchmark that seems to be superseded by JetStream.
Update: I got some feedback that old server CPU may not be most representative for testing desktop application. So I will try to re-run some of benchmarks on my skylake notebook to also verify that they reproduce. I will add them in red. I do not plan to re-run everything. I am not completely happy about the reproducibility of sunspider here, but I have disabled powersave, killed my .mozilla directory and switched to ice-wm. I skipped my clang build but added default Tumbleweed firefox for extra fun.
Speedometer is closer to the noise factor, but shows difference at least between GCC 8 binary and Firefox 63. It measures responsibility of the browser.
Update: local run seems to have less noise.
Dromaeo DOM is the first benchmark which is not part of the train run. It tests DOM and CSS queries. I show results of run using http://dromaeo.com/?dom|jslib|cssquery. This is subset of the full suite that is not very centric to the javascript JIT performance and I have earlier observed it is more sensitive to compiler generated code. I have run the default set of benchmarks earlier also observing a difference which was about 1.5% (comparing GCC 8 build with Firefox 64 official binary). They runs for a while, I will find time to re-run them later. From perf profiles I know that the JavaScript benchmark tests a lot of JIT generated code, some of JIT performance itself and simple C routines, such as UTF conversions.
You can check detailed comparison of individual runs. (order is the same as I run it: GCC 8, Firefox 63, Clang 7, Firefox 64). I am bit surprised by difference between Clang and Firefox 64 release.
MotionMark is fun to watch benchmark testing rendering speed. Eventually I got bored however and produced fan-art.
 |
| Hope they will stay friends :) |
Update: I have re-run this on my skylake notebook.
JetStream is testing performance of most advanced web applications. Seems you are better to build with old GCC in this case!
ARES-6 tests ECMAScript 6 applications. I do not know what it is, but I am sure it is important.
Runtime memory use
This I measured by letting the Firefox to start, observing resources in top and waiting for few seconds for number to settle down. I was hoping for more interesting numbers here because GCC with LTO has a code section reordering algorithms which was developed by Martin Liška and was motivated by Firefox. This is done by measuring the average time of first execution of every function and then ordering code segment in a way that during the startup just tiny portion of it is touched and execution is done in the increasing order.
It does not show much and the resource usage seems to be fully justified by the code segment size. At some point Firefox started to mmap whole binary to prevent page demand loading from seeking too much. This seems to be still the case today. I wonder how that works on SSD disks?
Build time and built-time memory usage
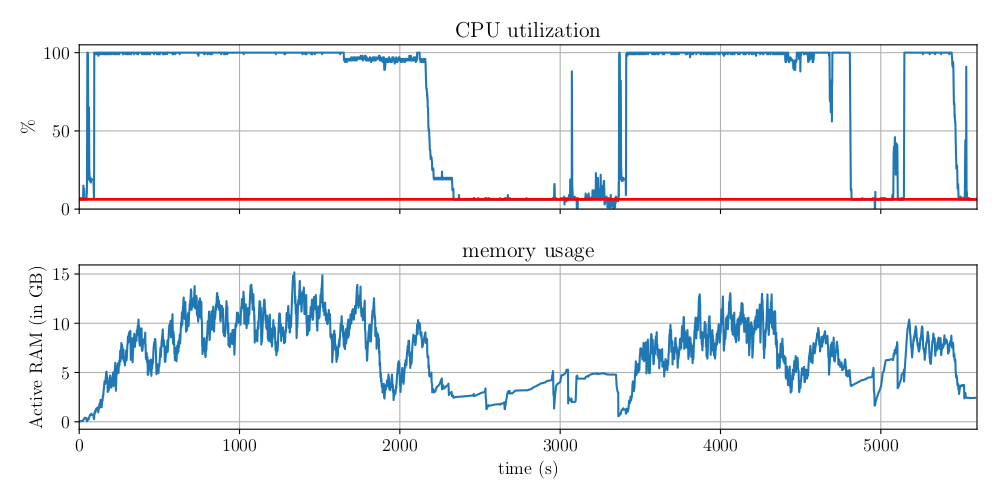
This is memory and CPU use graph I collected from builds. |
| Memory and CPU use during GCC 8 build |
 | |
| Memory and CPU use duuring LLVM build |
Note that reducing parallelism from 16 down will get you smaller peak memory use so Firefox should build with GCC on boxes with 10GB.
Update: Building Firefox with current snapshot of GCC 9 takes 93minutes, so 7% improvement and only 2% slower than my Clang build. Memory use is down to 15GB peak (still twice of Clang's) but more importantly the link-time optimization part should fit in 8GB box (GCC has garbage collector so if you have less memory than 64GB I use for testing, it will trade some memory for compile time).
 |
| Memory use of GCC 9 snapshot (Dec 16th 2018) |
Update: According to reddit post my Clang build procedure could be improved, because the default training run is very small. Instructions are here and here. I will give it a try.
Details of my setup
For my tests I use AMD Bulldozer based machine (AMD Opteron 6272) with 8 cores and 16 threads running Debian 9.6. My other machine is ThinkPad X260 notebook with Intel(R) Core(TM) i7-6600U CPU.I built GCC 8 from current SVN trunk configured with
and build with../configure --with-build-config=bootstrap-lto --disable-multilib --disable-werror --disable-plugin
make profiledbootstrap
I also tested GCC trunk (which is in early stage3 heading to GCC 9 release) with same configuration.Since LLVM webpage no longer has official binaries for debian I downloaded llvm 7 release and built it myself following the bootstrap and LTO+PGO procedure. For that one needs to first build LLVM+clang+lld+runtime with GCC, then build version collecting profile data and finally build LTO optimized binary with profile feedback. To gather profile data I used
And to obtain final build I use:/usr/bin/cmake -C ../llvm-7.0.0.src/tools/clang/cmake/caches/PGO.cmake ../llvm-7.0.0.src -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/aux/hubicka/llvm7-install-fdo -DLLVM_TARGETS_ TO_BUILD=X86 -DLLVM_BINUTILS_INCDIR=/aux/hubicka/binutils-install/include/ -G Ninja
It is first time I attempted to build PGO optimized clang so I hope I did that correctly./usr/bin/cmake -DCMAKE_C_COMPILER=/aux/hubicka/llvm7-install-fdo/bin/clang -DCMAKE_CXX_COMPILER=/aux/hubicka/llvm7-install-fdo/bin/clang++ -DLLVM_PROFDATA_FILE=/aux/hubicka/./build2/tool s/clang/stage2-instrumented-bins/tools/clang/utils/perf-training/clang.profdata ../llvm-7.0.0.src -DCMAKE_BUILD_TYPE=Release -DCMAKE_INSTALL_PREFIX=/aux/hubicka/llvm7-install-fdo -DLLVM_ TARGETS_TO_BUILD=X86 -DLLVM_BINUTILS_INCDIR=/aux/hubicka/binutils-install/include/ -G Ninja -DLLVM_ENABLE_LTO=Thin -DCMAKE_RANLIB=/aux/hubicka/llvm7-install-fdo/bin/llvm-ranlib -DCMAKE_AR=/aux/hubicka/llvm7-install-fdo/bin/llvm-ar
Update: According to reddit post my Clang build procedure could be improved, because the default training run is very small. Instructions are here and here. I will give it a try.
Finally I use pretty basic mozconfig:
mk_add_options MOZ_MAKE_FLAGS="-j16" CC=/aux/hubicka/trunk-install/bin/gcc CXX=/aux/hubicka/trunk-install/bin/g++ export PATH=/aux/hubicka/trunk-install/bin/:$PATH MYFLAGS="-O3" mk_add_options OS_CFLAGS="$MYFLAGS" mk_add_options OS_CXXFLAGS="$MYFLAGS" mk_add_options OS_LDFLAGS="$MYFLAGS" ac_add_options --enable-optimize=-O3 ac_add_options --enable-application=browser ac_add_options --enable-debug-symbols ac_add_options --disable-valgrind ac_add_options --enable-lto ac_add_options --enable-tests ac_add_options MOZ_PGO=1 export moz_telemetry_reporting=1 export mozilla_official=1 ac_add_options --enable-linker=gold export CFLAGS="$MYFLAGS" export CXXFLAGS="$MYFLAGS -fpermissive" export LDFLAGS="$MYFLAGS" mk_add_options MOZ_OBJDIR=<mydir>
I thus use gold for both GCC and Clang build. For clang I additionally need
ulimit -n 10240because it runs out of file descriptors during linking. This does not happen with lld, but then elfhack fails.
I have set power saving to performance for my testing.
Great job, Honza, thoroughly done. It seems like Fedora jumped too soon. Such a binary size growth is horrible
ReplyDeleteThanks for your efforts on this! I download the tarball and it seems to be indeed faster than the official build... maybe just because of the feeling that I downloaded a fresh build made by you! :-)
ReplyDeleteI really appreciate your hard work on LTO with GCC. Without your efforts no one would use LTO with GCC as it has produced slower binaries for many years (or even decades?!). I try LTO about once per year on my C++ HPC projects but so far LTO still produces slower binaries for myself. But I am reasonably optimistic that LTO will eventually work great.
ReplyDeleteNote that profile guided optimization already works great with GCC and often produces faster binaries. However one drawback of PGO is that if some parts of the code have not been profiled this code often runs slower in the final binary. For this reason I still compile my code using only -O3.
It would be great to have some sort of testcase, so we can look at it. LTO inlning is not easiest thing to tune.
DeleteHey,
ReplyDeleteVery interesting article. And very factual and honest especially for a hard working gcc developer. ;)
To be able to compare both compilers is indeed a fine way to catch finer performance metrics and I bet it is a quite sane practice that can help both compilers in the end. Thus, I can't wait for the gcc 9 comparison.
For those like me who don't know all the intrinsics, could you describe a bit what is 'train run'?
Thanks again
Less hard working GCC developers tends to be less honest indeed! ;)
DeleteWhen you want to build with profile feedback you need to do
1) build with -fprofile-generate
2) gather some profile data by running your program
3) rebuild with -fprofile-use
2) is what I refer to as train run. I will update the text to explain this, too :)
Thanks for the informative article. It was very insightful. To echo Yoan's comment, I appreciated your honesty. Gcc is in a good place in my opinion.
ReplyDeleteOne thing I struggle with grasping is the state/quality of generated debug information when using LTO. My understanding is that before gcc-8, it was not so great. What is the current standing with gcc 8/9?
Lastly regarding your comment about vectorization, are you hinting at the fact that vectorization may move to -O2? Can you please clarify?
Gavin.
Before GCC 8, the debug info was indeed pretty bad - you got C-like debug for all languages. With GCC 8 Richard Biener merged in early debug http://hubicka.blogspot.com/2018/06/gcc-8-link-time-and-interprocedural.html
Deleteand the debug info should be at same level as no-lto (and in my experience it works).
There are two things that bugs me - the libbacktrace used by GCC to output crash info does not parse well the new dwarf and won't output function names (outputs only files/lines) and gdb is slow on parsing the debug info on larger binaries.
Those are issues outside GCC itself and hope they will be solved now when LTO is getting better adoption :)
Thanks! Gavin.
Delete